
分布式定时任务Quartz学习与使用
时间轮介绍
从具体实现来看,时间轮 是一个基于 「数组」 实现的 「循环队列」 ,数组的每个元素被称为 「槽(slot)」 ,每个槽中存储着一个 「任务列表」 ,这个任务列表的实现较为多样,可以是 「由双向链表实现」 ,也可以是 「由数组实现」。除了基本的存储结构,时间轮还有一根用于指示当前时间的指针,这根指针同时也用于触发所指向的时间槽内任务。该指针以恒定的速度旋转,每经过一个槽即走过一个单位时间*(所以也可以将槽称为时间槽,因为它即表示时间刻度,也表示存储空间)*,旋转一圈则走过时间轮的一个生命周期。
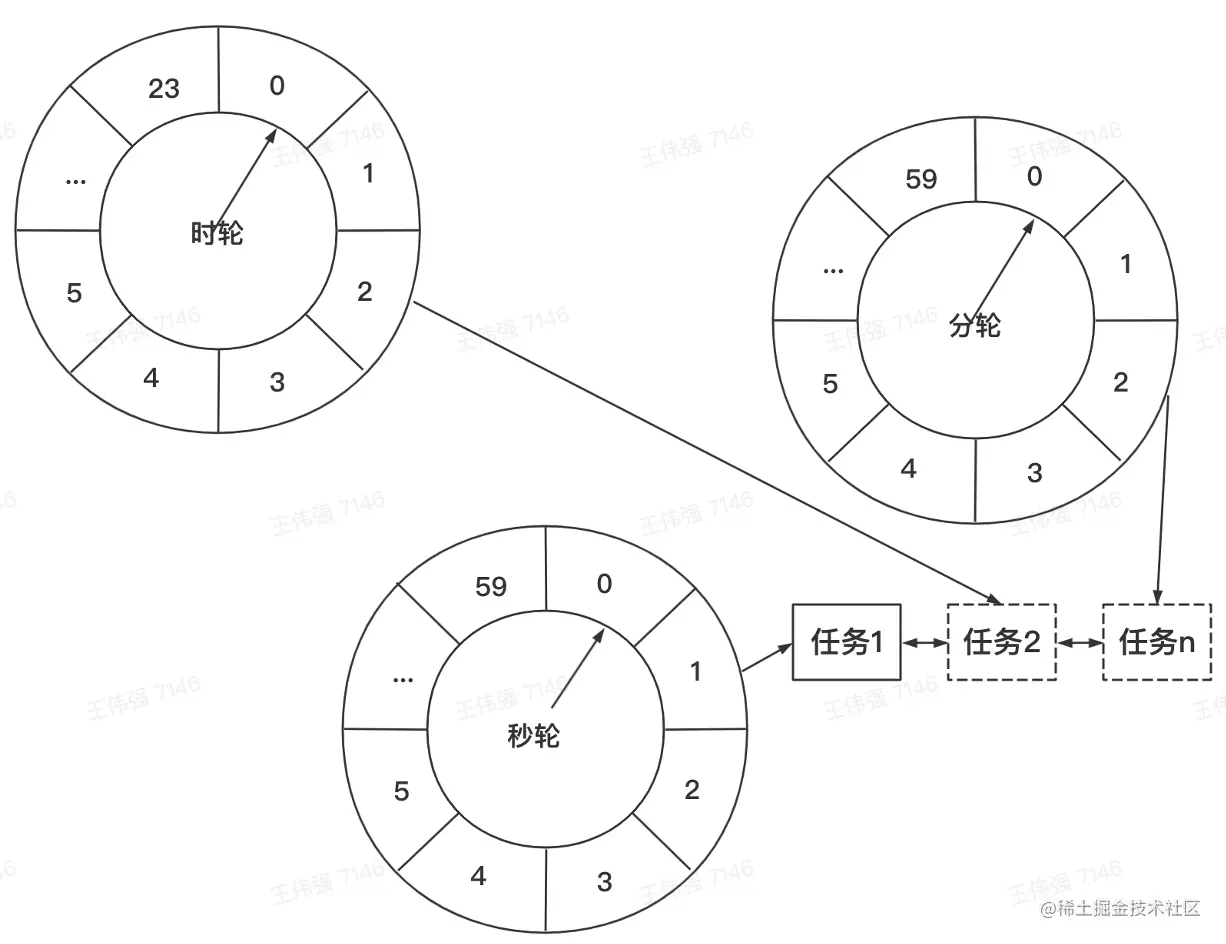
而上图采用的是多层级时间轮
多层级时间轮从逻辑上和我们日常使用的时钟颇为相似,上一层级的时间轮中的一个时间槽(单位时间)等于下一层级的时间轮的一个时间周期。
Quartz核心概念
Scheduler为调度器负责整个定时系统的调度,内部通过线程池进行调度,下文阐述。
Trigger为触发器记录着调度任务的时间规则,主要有四种类型:SimpleTrigger、CronTrigger、DataIntervalTrigger、NthIncludedTrigger,在项目中常用的为:SimpleTrigger和CronTrigger。
JobDetail为定时任务的信息载体,可以记录Job的名字、组及任务执行的具体类和任务执行所需要的参数
Job为任务的真正执行体,承载着具体的业务逻辑。
先由SchedulerFactory创建Scheduler调度器后,由调度器去调取即将执行的Trigger,执行时获取到对于的JobDetail信息,找到对应的Job类执行业务逻辑。
Spring Boot 实现
下面实现的是一个使用Quartz定时将Redis的数据传到mysql中同步。
1. 引入依赖
1 | <dependency> |
2. 配置Quartz
1 |
|
JobDetail
JobDetail对象是在将job加入scheduler时,由客户端程序(你的程序)创建的。它包含job的各种属性设置,以及用于存储job实例状态信息的JobDataMap。
在创建JobDetail时,我们需要将要执行的job的类名传给了JobDetail,这样scheduler就知道了要执行何种类型的job。
我们还可以给通过JobDetail给job设置name和group。
每次当scheduler执行job时,在调用其execute(…)方法之前会创建该类的一个新的实例;执行完毕,对该实例的引用就被丢弃了,实例会被垃圾回收;这种执行策略带来的一个后果是,job必须有一个无参的构造函数(当使用默认的JobFactory时);另一个后果是,在job类中,不应该定义有状态的数据属性,因为在job的多次执行中,这些属性的值不会保留。
3. Job类实现
1 |
|
Job
定义一个实现了Job的类(或者QuartzJobBean),这个类表名job需要完成那些业务。
当一个Job被trigger被触发触发时,execute()方法会被scheduler的一个工作线程调用;传递给execute()方法的JobExecutionContext对象中保存着该job运行时的一些信息 ,比如执行job的scheduler的引用,触发job的trigger的引用,JobDetail对象引用,以及一些其它信息。
Job DataMap
JobDataMap
JobDataMap中可以包含不限量的(序列化的)数据对象,在job实例执行的时候,可以使用其中的数据;JobDataMap是Java Map接口的一个实现,额外增加了一些便于存取基本类型的数据的方法。
将job加入到scheduler之前,在构建JobDetail时,可以将数据放入JobDataMap。
1 | //构建JobDetail实例 |
1 | System.err.println(context.getJobDetail().getJobDataMap().get("jobcc")); |